Среднее квадратичное отклонение какое должно быть. Среднее квадратическое отклонение простое
Стандартное отклонение - классический индикатор изменчивости из описательной статистики.
Стандартное отклонение , среднеквадратичное отклонение, СКО, выборочное стандартное отклонение (англ. standard deviation, STD, STDev) - очень распространенный показатель рассеяния в описательной статистике. Но, т.к. технический анализ сродни статистике, данный показатель можно (и нужно) использовать в техническом анализе для обнаружения степени рассеяния цены анализируемого инструмента во времени. Обозначается греческим символом Сигма «σ».
Спасибо Карлам Гауссу и Пирсону за то, что мы имеем возможность пользоваться стандартным отклонением.
Используя стандартное отклонение в техническом анализе , мы превращаем этот «показатель рассеяния » в «индикатор волатильности «, сохраняя смысл, но меняя термины.
Что представляет собой стандартное отклонение
Но помимо промежуточных вспомогательных вычислений, стандартное отклонение вполне приемлемо для самостоятельного вычисления и применения в техническом анализе. Как отметил активный читатель нашего журнала burdock, «до сих пор не пойму, почему СКО не входит в набор стандартных индикаторов отечественных диллинговых центров «.
Действительно, стандартное отклонение может классическим и «чистым» способом измерить изменчивость инструмента . Но к сожалению, этот индикатор не так распространен в анализе ценных бумаг .
Применение стандартного отклонения
Вручную вычислить стандартное отклонение не очень интересно , но полезно для опыта. Стандартное отклонение можно выразить формулой STD=√[(∑(x-x ) 2)/n] , что звучит как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
Если количество элементов в выборке превышает 30, то знаменатель дроби под корнем принимает значение n-1. Иначе используется n.
Пошагово вычисление стандартного отклонения :
- вычисляем среднее арифметическое выборки данных
- отнимаем это среднее от каждого элемента выборки
- все полученные разницы возводим в квадрат
- суммируем все полученные квадраты
- делим полученную сумму на количество элементов в выборке (или на n-1, если n>30)
- вычисляем квадратный корень из полученного частного (именуемого дисперсией )
Для расчетов средней геометрической простой используется формула:
Геометрическая взвешенная
Для определения средней геометрической взвешенной применяется формула:
редние диаметры колес, труб, средние стороны квадратов определяются при помощи средней квадратической.
Среднеквадратические величины используются для расчета некоторых показателей, например коэффициент вариации, характеризующего ритмичность выпуска продукции. Здесь определяют среднеквадратическое отклонение от планового выпуска продукции за определенный период по следующей формуле:
Эти величины точно характеризуют изменение экономических показателей по сравнению с их базисной величиной, взятое в его усредненной величине.
Квадратическая простая
Средняя квадратическая простая вычисляется по формуле:

Квадратическая взвешенная
Средняя квадратическая взвешенная равна:

22. Абсолютные показатели вариации включают:
размах вариации
среднее линейное отклонение
дисперсию
среднее квадратическое отклонение
Размах вариации (r)
Размах вариации - это разность между максимальным и минимальным значениями признака
Он показывает пределы, в которых изменяется величина признака в изучаемой совокупности.
Опыт работы у пяти претендентов на предшествующей работе составляет: 2,3,4,7 и 9 лет. Решение: размах вариации = 9 - 2 = 7 лет.
Для обобщенной характеристики различий в значениях признака вычисляют средние показатели вариации, основанные на учете отклонений от средней арифметической. За отклонение от средней принимается разность .
При этом во избежании превращения в нуль суммы отклонений вариантов признака от средней (нулевое свойство средней) приходится либо не учитывать знаки отклонения, то есть брать эту сумму по модулю , либо возводить значения отклонений в квадрат
Среднее линейное и квадратическое отклонение
Среднее линейное отклонение - этосредняя арифметическая из абсолютных отклонений отдельных значений признака от средней.
Среднее линейное отклонение простое:
Опыт работы у пяти претендентов на предшествующей работе составляет: 2,3,4,7 и 9 лет.
В нашем примере: лет;
Ответ: 2,4 года.
Среднее линейное отклонение взвешенное применяется для сгруппированных данных:
Среднее линейное отклонение в силу его условности применяется на практике сравнительно редко (в частности, для характеристики выполнения договорных обязательств по равномерности поставки; в анализе качества продукции с учетом технологических особенностей производства).
Среднее квадратическое отклонение
Наиболее совершенной характеристикой вариации является среднее квадратическое откложение, которое называют стандартом (или стандартным отклонение). Среднее квадратическое отклонение () равно квадратному корню из среднего квадрата отклонений отдельных значений признака отсредней арифметической:
Среднее квадратическое отклонение простое:


Среднее квадратическое отклонение взвешенное применяется для сгруппированных данных:

Между средним квадратическим и средним линейным отклонениями в условиях нормального распределения имеет место следующее соотношение: ~ 1,25.
Среднее квадратическое отклонение, являясь основной абсолютной мерой вариации, используется при определении значений ординат кривой нормального распределения, в расчетах, связанных с организацией выборочного наблюдения и установлением точности выборочных характеристик, а также при оценке границ вариации признака в однородной совокупности.
$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
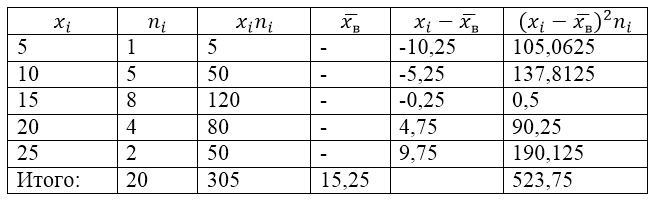
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
Занятие №4
Тема: «Описательная статистика. Показатели разнообразия признака в совокупности»
Основными критериями разнообразия признака в статистической совокупности являются: лимит, амплитуда, среднее квадратическое отклонение, коэффициент осцилляции и коэффициент вариации. На предыдущем занятии обсуждалось, что средние величины дают лишь обобщающую характеристику изучаемого признака в совокупности и не учитывают значения отдельных его вариант: минимальное и максимальное значения, выше среднего, ниже среднего и т.д.
Пример. Средние величины двух разных числовых последовательностей: -100; -20; 100; 20 и 0,1; -0,2; 0,1 абсолютно одинаковы и равны О. Однако, диапазоны разброса данных этих последовательностей относительного среднего значения сильно различны.
Определение перечисленных критериев разнообразия признака прежде всего осуществляется с учетом его значения у отдельных элементов статистической совокупности.
Показатели измерения вариации признака бывают абсолютные и относительные . К абсолютным показателям вариации относят: размах вариации, лимит, среднее квадратическое отклонение, дисперсию. Коэффициент вариации и коэффициент осцилляции относятся к относительным показателям вариации.
Лимит (lim)– это критерий, который определяется крайними значениями вариант в вариационном ряду. Другими словами, данный критерий ограничивается минимальной и максимальной величинами признака:
Амплитуда (Am) или размах вариации – это разность крайних вариант. Расчет данного критерия осуществляется путем вычитания из максимального значения признака его минимального значения, что позволяет оценить степень разброса вариант:
Недостатком лимита и амплитуды как критериев вариабельности является то, что они полностью зависят от крайних значений признака в вариационном ряду. При этом не учитываются колебания значений признака внутри ряда.
Наиболее полную характеристику разнообразия признака в статистической совокупности дает среднее квадратическое отклонение (сигма), которое является общей мерой отклонения вариант от своей средней величины. Среднее квадратическое отклонение часто называют также стандартным отклонением .
В основе среднего квадратического отклонения лежит сопоставление каждой варианты со средней арифметической данной совокупности. Так как в совокупности всегда будут варианты как меньше, так и больше, чем она, то сумма отклонений , имеющих знак "", будет погашаться суммой отклонений, имеющих знак "", т.е. сумма всех отклонений равна нулю. Для того, чтобы избежать влияния знаков разностей берут отклонения вариант от среднего арифметического в квадрате, т.е. . Сумма квадратов отклонений не равняется нулю. Чтобы получить коэффициент, способный измерить изменчивость, берут среднее от суммы квадратов – это величина носит название дисперсии:

По смыслу, дисперсия – это средний квадрат отклонений индивидуальных значений признака от его средней величины. Дисперсия – квадрат среднего квадратического отклонения .
Дисперсия является размерной величиной (именованной). Так, если варианты числового ряда выражены в метрах, то дисперсия дает квадратные метры; если варианты выражены в килограммах, то дисперсия дает квадрат этой меры (кг 2), и т.д.
Среднее квадратическое отклонение – квадратный корень из дисперсии:
, то при расчете дисперсии и среднего квадратического отклонения в знаменателе дроби вместо необходимо ставить .
Расчет среднего квадратического отклонения можно разбить на шесть этапов, которые необходимо осуществить в определенной последовательности:
Применение среднеквадратического отклонения:
а) для суждения о колеблемости вариационных рядов и сравнительной оценки типичности (представительности) средних арифметических величин. Это необходимо в дифференциальной диагностике при определении устойчивости признаков.
б) для реконструкции вариационного ряда, т.е. восстановления его частотной характеристики на основе правила «трех сигм» . В интервале (М±3σ) находится 99,7% всех вариант ряда, в интервале (М±2σ) - 95,5% и в интервале (М±1σ) - 68,3% вариант ряда (рис.1).
в) для выявления «выскакивающих» вариант
г) для определения параметров нормы и патологии с помощью сигмальных оценок
д) для расчета коэффициента вариации
е) для расчета средней ошибки средней арифметической величины.
Для характеристики любой генеральной совокупности, имеющей нормальный тип распределения , достаточно знать два параметра: среднюю арифметическую и среднее квадратическое отклонение.

Рисунок 1. Правило «трех сигм»
Пример.
В педиатрии среднеквадратическое отклонение используется для оценки физического развития детей путем сравнения данных конкретного ребенка с соответствующими стандартными показателями. За стандарт принимаются средние арифметические показатели физического развития здоровых детей. Сравнение показателей со стандартами проводят по специальным таблицам, в которых стандарты приводятся вместе с соответствующими им сигмальными шкалами. Считается, что если показатель физического развития ребенка находится в пределах стандарт (среднее арифметическое) ±σ, то физическое развитие ребенка (по этому показателю) соответствует норме. Если показатель находится в пределах стандарт ±2σ, то имеется незначительное отклонение от нормы. Если показатель выходит за эти границы, то физическое развитие ребенка резко отличается от нормы (возможна патология).
Кроме показателей вариации, выраженных в абсолютных величинах, в статистическом исследовании используются показатели вариации, выраженные в относительных величинах. Коэффициент осцилляции - это отношение размаха вариации к средней величине признака. Коэффициент вариации - это отношение среднего квадратического отклонения к средней величине признака. Как правило, эти величины выражаются в процентах.
Формулы расчета относительных показателей вариации:
Из приведенных формул видно, что чем больше коэффициент V приближен к нулю, тем меньше вариация значений признака. Чем больше V , тем более изменчив признак.
В статистической практике наиболее часто применяется коэффициент вариации. Он используется не только для сравнительной оценки вариации, но и для характеристики однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33% (для распределений, близких к нормальному). Арифметически отношение σ и средней арифметической нивелирует влияние абсолютной величины этих характеристик, а процентное соотношение делает коэффициент вариации величиной безразмерной (неименованной).
Полученное значение коэффициента вариации оценивается в соответствии с ориентировочными градациями степени разнообразия признака:
Слабое - до 10 %
Среднее - 10 - 20 %
Сильное - более 20 %
Использование коэффициента вариации целесообразно в случаях, когда приходится сравнивать признаки разные по своей величине и размерности.
Отличие коэффициента вариации от других критериев разброса наглядно демонстрирует пример .
Таблица 1
Состав работников промышленного предприятия
На основании приведенных в примере статистических характеристик можно сделать вывод об относительной однородности возрастного состава и образовательного уровня работников предприятия при низкой профессиональной устойчивости обследованного контингента. Нетрудно заметить, что попытка судить об этих социальных тенденциях по среднему квадратическому отклонению привела бы к ошибочному заключению, а попытка сравнения учетных признаков «стаж работы» и «возраст» с учетным признаком «образование» вообще была бы некорректной из-за разнородности этих признаков.
Медиана и перцентили
Для порядковых (ранговых) распределений, где критерием середины ряда является медиана, среднеквадратическое отклонение и дисперсия не могут служить характеристиками рассеяния вариант.
То же свойственно и для открытых вариационных рядов. Указанное обстоятельство связано с тем, что отклонения, по которым вычисляются дисперсия и σ, отсчитываются от среднего арифметического, которое не вычисляется в открытых вариационных рядах и в рядах распределений качественных признаков. Поэтому для сжатого описания распределений используется другой параметр разброса – квантиль (синоним - «nерцентиль»), пригодный для описания качественных и количественных признаков при любой форме их распределения. Этот параметр может использоваться и для перевода количественных признаков в качественные. В этом случае такие оценки присваиваются в зависимости от того, какому по порядку квантилю соответствует та или иная конкретная варианта.
В практике медико-биологических исследований наиболее часто используются следующие квантили:
– медиана;
, – квартили (четверти), где – нижний квартиль, – верхний квартиль.
Квантили делят область возможных изменений вариант в вариационном ряду на определенные интервалы. Медиана (квантиль) – это варианта, которая находится в середине вариационного ряда и делит этот ряд пополам, на две равные части (0,5 и 0,5 ). Квартиль делит ряд на четыре части: первая часть (нижний квартиль) – это варианта, отделяющая варианты, числовые значения которых не превышают 25% максимально возможного в данном ряду, квартиль отделяет варианты с числовым значением до 50% от максимально возможного. Верхний квартиль () отделяет варианты величиной до 75% от максимально возможных значений.
В случае асимметричности распределения переменной относительно среднего арифметического для его характеристики используются медиана и квартили. В этом случае используется следующая форма отображения средней величины – Ме (;). Например , исследуемый признак – «срок, в котором ребенок начал самостоятельно ходить» - в исследуемой группе имеет ассиметричное распределение. При этом, нижнему квартилю () соответствует срок начала ходьбы – 9,5 месяцев, медиане – 11 месяцев, верхнему квартилю () – 12 месяцев. Соответственно, характеристика средней тенденции указанного признака будет представлена, как 11 (9,5; 12) месяцев.
Оценка статистической значимости результатов исследования
Под статистической значимостью данных понимают степень их соответствия отображаемой действительности, т.е. статистически значимыми данными считаются те, которые не искажают и правильно отражают объективную реальность.
Оценить статистическую значимость результатов исследования – означает определить, с какой вероятностью возможно перенести результаты, полученные на выборочной совокупности, на всю генеральную совокупность. Оценка статистической значимости необходима для понимания того, насколько по части явления можно судить о явлении в целом и его закономерностях.
Оценка статистической значимости результатов исследования складывается из:
1. ошибок репрезентативности (ошибок средних и относительных величин) - m ;
2. доверительных границ средних или относительных величин;
3. достоверности разности средних или относительных величин по критерию t .
Стандартная ошибка средней арифметической или ошибка репрезентативности характеризует колебания средней. При этом необходимо отметить, что чем больше объем выборки, тем меньше разброс средних величин. Стандартная ошибка среднего вычисляется по формуле:
В современной научной литературе средняя арифметическая записывается вместе с ошибкой репрезентативности:
или вместе со среднеквадратическим отклонением:
В качестве примера рассмотрим данные по 1500 городских поликлиник страны (генеральная совокупность). Среднее число пациентов, обслуживающихся в поликлинике равно 18150 человек. Случайный отбор 10 % объектов (150 поликлиник) дает среднее число пациентов, равное 20051 человек. Ошибка выборки, очевидно связанная с тем, что не все 1500 поликлиник попали в выборку, равна разности между этими средними – генеральным средним (M ген) и выборочным средним (М выб). Если сформировать другую выборку того же объема из нашей генеральной совокупности, она даст другую величину ошибки. Все эти выборочные средние при достаточно больших выборках распределены нормально вокруг генеральной средней при достаточно большом числе повторений выборки одного и того же числа объектов из генеральной совокупности. Стандартная ошибка среднего m - это неизбежный разброс выборочных средних вокруг генеральной средней.
В случае, когда результаты исследования представлены относительными величинами (например, процентными долями) – рассчитывается стандартная ошибка доли:
![]()
где P – показатель в %, n – количество наблюдений.
Результат отображается в виде (P ± m)%. Например, процент выздоровления среди больных составил (95,2±2,5)%.
В том случае, если число элементов совокупности , то при расчете стандартных ошибок среднего и доли в знаменателе дроби вместо необходимо ставить .
Для нормального распределения (распределение выборочных средних является нормальным) известно, какая часть совокупности попадает в любой интервал вокруг среднего значения. В частности:
На практике проблема заключается в том, что характеристики генеральной совокупности нам неизвестны, а выборка делается именно с целью их оценки. Это означает, что если мы будем делать выборки одного и того же объема n из генеральной совокупности, то в 68,3% случаев на интервале будет находиться значение M (оно же в 95,5% случаев будет находиться на интервале и в 99,7% случаев – на интервале).
Поскольку реально делается только одна выборка, то формулируется это утверждение в терминах вероятности: с вероятностью 68,3% среднее значение признака в генеральной совокупности заключено в интервале, с вероятностью 95,5% - в интервале и т.д.
На практике вокруг выборочного значения строится такой интервал, который бы с заданной (достаточно высокой) вероятностью – доверительной вероятностью – «накрывал» бы истинное значение этого параметра в генеральной совокупности. Этот интервал называется доверительным интервалом .
Доверительная вероятность P – это степень уверенности в том, что доверительный интервал действительно будет содержать истинное (неизвестное) значение параметра в генеральной совокупности.
Например, если доверительная вероятность Р равна 90%, то это означает, что 90 выборок из 100 дадут правильную оценку параметра в генеральной совокупности. Соответственно, вероятность ошибки, т.е. неверной оценки генерального среднего по выборке, равна в процентах: . Для данного примера это значит, что 10 выборок из 100 дадут неверную оценку.
Очевидно, что степень уверенности (доверительная вероятность) зависит от величины интервала: чем шире интервал, тем выше уверенность, что в него попадет неизвестное значение для генеральной совокупности . На практике для построения доверительного интервала берется, как минимум, удвоенная ошибка выборки, чтобы обеспечить уверенность не менее 95,5%.
Определение доверительных границ средних и относительных величин позволяет найти два их крайних значения – минимально возможное и максимально возможное, в пределах которых изучаемый показатель может встречаться во всей генеральной совокупности. Исходя из этого, доверительные границы (или доверительный интервал) - это границы средних или относительных величин, выход за пределы которых вследствие случайных колебаний имеет незначительную вероятность.
Доверительный интервал может быть переписан в виде: , где t – доверительный критерий.
Доверительные границы средней арифметической величины в генеральной совокупности определяют по формуле:
М ген = М выб + t m M
для относительной величины:
Р ген = Р выб + t m Р
где М ген и Р ген - значения средней и относительной величины для генеральной совокупности; М выб и Р выб - значения средней и относительной величины, полученные на выборочной совокупности; m M и m P - ошибки средней и относительной величин; t - доверительный критерий (критерий точности, который устанавливается при планировании исследования и может быть равен 2 или 3); t m - это доверительный интервал или Δ – предельная ошибка показателя, полученного при выборочном исследовании.
Следует отметить, что величина критерия t в определенной мере связана с вероятностью безошибочного прогноза (р), выраженной в %. Ее избирает сам исследователь, руководствуясь необходимостью получить результат с нужной степенью точности. Так, для вероятности безошибочного прогноза 95,5% величина критерия t составляет 2, для 99,7% - 3.
Приведенные оценки доверительного интервала приемлемы лишь для статистических совокупностей с количеством наблюдений более 30. При меньшем объеме совокупности (малых выборках) для определения критерия t пользуются специальными таблицами. В данных таблицах искомое значение находится на пересечении строки, соответствующей численности совокупности (n-1) , и столбца, соответствующего уровню вероятности безошибочного прогноза (95,5%; 99,7%), выбранному исследователем. В медицинских исследованиях при установлении доверительных границ любого показателя принята вероятность безошибочного прогноза 95,5% и более. Это означает, что величина показателя, полученная на выборочной совокупности должна встречаться в генеральной совокупности как минимум в 95,5% случаев.
Вопросы по теме занятия:
Актуальность показателей разнообразия признака в статистической совокупности.
Общая характеристика абсолютных показателей вариации.
Среднее квадратическое отклонение, расчет, применение.
Относительные показатели вариации.
Медиана, квартильная оценка.
Оценка статистической значимости результатов исследования.
Стандартная ошибка средней арифметической, формула расчета, пример использования.
Расчет доли и ее стандартной ошибки.
Понятие доверительной вероятности, пример использования.
10. Понятие доверительного интервала, его применение.
Тестовые задания по теме с эталонами ответов:
1. К АБСОЛЮТНЫМ ПОКАЗАТЕЛЯМ ВАРИАЦИИ ОТНОСИТСЯ
1) коэффициент вариации
2) коэффициент осцилляции
4) медиана
2. К ОТНОСИТЕЛЬНЫМ ПОКАЗАТЕЛЯМ ВАРИАЦИИ ОТНОСИТСЯ
1) дисперсия
4) коэффициент вариации
3. КРИТЕРИЙ, КОТОРЫЙ ОПРЕДЕЛЯЕТСЯ КРАЙНИМИ ЗНАЧЕНИЯМИ ВАРИАНТ В ВАРИАЦИОННОМ РЯДУ
2) амплитуда
3) дисперсия
4) коэффициент вариации
4. РАЗНОСТЬ КРАЙНИХ ВАРИАНТ – ЭТО
2) амплитуда
3) среднее квадратичное отклонение
4) коэффициент вариации
5. СРЕДНИЙ КВАДРАТ ОТКЛОНЕНИЙ ИНДИВИДУАЛЬНЫХ ЗНАЧЕНИЙ ПРИЗНАКА ОТ ЕГО СРЕДНЕЙ ВЕЛИЧИНЫ – ЭТО
1) коэффициент осцилляции
2) медиана
3) дисперсия
6. ОТНОШЕНИЕ РАЗМАХА ВАРИАЦИИ К СРЕДНЕЙ ВЕЛИЧИНЕ ПРИЗНАКА – ЭТО
1) коэффициент вариации
2) среднее квадратичное отклонение
4) коэффициент осцилляции
7. ОТНОШЕНИЕ СРЕДНЕГО КВАДРАТИЧНОГО ОТКЛОНЕНИЯ К СРЕДНЕЙ ВЕЛИЧИНЕ ПРИЗНАКА – ЭТО
1) дисперсия
2) коэффициент вариации
3) коэффициент осцилляции
4) амплитуда
8. ВАРИАНТА, КОТОРАЯ НАХОДИТСЯ В СЕРЕДИНЕ ВАРИАЦИОННОГО РЯДА И ДЕЛИТ ЕГО НА ДВЕ РАВНЫЕ ЧАСТИ – ЭТО
1) медиана
3) амплитуда
9. В МЕДИЦИНСКИХ ИССЛЕДОВАНИЯХ ПРИ УСТАНОВЛЕНИИ ДОВЕРИТЕЛЬНЫХ ГРАНИЦ ЛЮБОГО ПОКАЗАТЕЛЯ ПРИНЯТА ВЕРОЯТНОСТЬ БЕЗОШИБОЧНОГО ПРОГНОЗА
10. ЕСЛИ 90 ВЫБОРОК ИЗ 100 ДАЮТ ПРАВИЛЬНУЮ ОЦЕНКУ ПАРАМЕТРА В ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ, ТО ЭТО ОЗНАЧАЕТ, ЧТО ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ P РАВНА
11. В СЛУЧАЕ, ЕСЛИ 10 ВЫБОРОК ИЗ 100 ДАЮТ НЕВЕРНУЮ ОЦЕНКУ, ВЕРОЯТНОСТЬ ОШИБКИ РАВНА
12. ГРАНИЦЫ СРЕДНИХ ИЛИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН, ВЫХОД ЗА ПРЕДЕЛЫ КОТОРЫХ ВСЛЕДСТВИЕ СЛУЧАЙНЫХ КОЛЕБАНИЙ ИМЕЕТ НЕЗНАЧИТЕЛЬНУЮ ВЕРОЯТНОСТЬ – ЭТО
1) доверительный интервал
2) амплитуда
4) коэффициент вариации
13. МАЛОЙ ВЫБОРКОЙ СЧИТАЕТСЯ ТА СОВОКУПНОСТЬ, В КОТОРОЙ
1) n меньше или равно 100
2) n меньше или равно 30
3) n меньше или равно 40
4) n близко к 0
14. ДЛЯ ВЕРОЯТНОСТИ БЕЗОШИБОЧНОГО ПРОГНОЗА 95% ВЕЛИЧИНА КРИТЕРИЯ t СОСТАВЛЯЕТ
15. ДЛЯ ВЕРОЯТНОСТИ БЕЗОШИБОЧНОГО ПРОГНОЗА 99% ВЕЛИЧИНА КРИТЕРИЯ t СОСТАВЛЯЕТ
16. ДЛЯ РАСПРЕДЕЛЕНИЙ, БЛИЗКИХ К НОРМАЛЬНОМУ, СОВОКУПНОСТЬ СЧИТАЕТСЯ ОДНОРОДНОЙ, ЕСЛИ КОЭФФИЦИЕНТ ВАРИАЦИИ НЕ ПРЕВЫШАЕТ
17. ВАРИАНТА, ОТДЕЛЯЮЩАЯ ВАРИАНТЫ, ЧИСЛОВЫЕ ЗНАЧЕНИЯ КОТОРЫХ НЕ ПРЕВЫШАЮТ 25% МАКСИМАЛЬНО ВОЗМОЖНОГО В ДАННОМ РЯДУ – ЭТО
2) нижний квартиль
3) верхний квартиль
4) квартиль
18. ДАННЫЕ, КОТОРЫЕ НЕ ИСКАЖАЮТ И ПРАВИЛЬНО ОТРАЖАЮТ ОБЪЕКТИВНУЮ РЕАЛЬНОСТЬ, НАЗЫВАЮТСЯ
1) невозможные
2) равновозможные
3) достоверные
4) случайные
19. СОГЛАСНО
ПРАВИЛУ "ТРЕХ СИГМ", ПРИ НОРМАЛЬНОМ
РАСПРЕДЕЛЕНИИ ПРИЗНАКА В ПРЕДЕЛАХ
 БУДЕТ НАХОДИТЬСЯ
БУДЕТ НАХОДИТЬСЯ
1) 68,3% вариант
Математическое ожидание и дисперсия
Пусть мы измеряем случайную величину N раз, например, десять раз измеряем скорость ветра и хотим найти среднее значение. Как связано среднее значение с функцией распределения?
Будем кидать игральный кубик большое количество раз. Количество очков, которое выпадет на кубике при каждом броске, является случайной величиной и может принимать любые натуральные значения от 1 до 6. Среднее арифметическое выпавших очков, подсчитанных за все броски кубика, тоже является случайной величиной, однако при больших N оно стремится ко вполне конкретному числу – математическому ожиданию M x . В данном случае M x = 3,5.
Каким образом получилась эта величина? Пусть в N испытаниях раз выпало 1 очко, раз – 2 очка и так далее. Тогда При N → ∞ количество исходов, в которых выпало одно очко, Аналогично, Отсюда
Модель 4.5. Игральные кости
Предположим теперь, что мы знаем закон распределения случайной величины x , то есть знаем, что случайная величина x может принимать значения x 1 , x 2 , ..., x k с вероятностями p 1 , p 2 , ..., p k .
Математическое ожидание M x случайной величины x равно:
Ответ. 2,8.
Математическое ожидание не всегда является разумной оценкой какой-нибудь случайной величины. Так, для оценки средней заработной платы разумнее использовать понятие медианы, то есть такой величины, что количество людей, получающих меньшую, чем медиана, зарплату и большую, совпадают.
Медианой случайной величины называют число x 1/2 такое, что p (x < x 1/2) = 1/2.
Другими словами, вероятность p 1 того, что случайная величина x окажется меньшей x 1/2 , и вероятность p 2 того, что случайная величина x окажется большей x 1/2 , одинаковы и равны 1/2. Медиана определяется однозначно не для всех распределений.
Вернёмся к случайной величине x , которая может принимать значения x 1 , x 2 , ..., x k с вероятностями p 1 , p 2 , ..., p k .
Дисперсией случайной величины x называется среднее значение квадрата отклонения случайной величины от её математического ожидания:
Пример 2
В условиях предыдущего примера вычислить дисперсию и среднеквадратическое отклонение случайной величины x .
Ответ. 0,16, 0,4.
Модель 4.6. Стрельба в мишень
Пример 3
Найти распределение вероятности числа очков, выпавших на кубике с первого броска, медиану, математическое ожидание, дисперсию и среднеквадратичное отклонение.
Выпадение любой грани равновероятно, так что распределение будет выглядеть так:
Среднеквадратичное отклонение Видно, что отклонение величины от среднего значения очень велико.
Свойства математического ожидания:
- Математическое ожидание суммы независимых случайных величин равно сумме их математических ожиданий:
Пример 4
Найти математическое ожидание суммы и произведения очков, выпавшей на двух кубиках.
В примере 3 мы нашли, что для одного кубика M (x ) = 3,5. Значит, для двух кубиков
Свойства дисперсии:
- Дисперсия суммы независимых случайных величин равно сумме дисперсий:
D x + y = D x + D y .
Пусть за N бросков на кубике выпало y очков. Тогда
Этот результат верен не только для бросков кубика. Он во многих случаях определяет точность измерения математического ожидания опытным путем. Видно, что при увеличении количества измерений N разброс значений вокруг среднего, то есть среднеквадратичное отклонение, уменьшается пропорционально
Дисперсия случайной величины связана с математическим ожиданием квадрата этой случайной величины следующим соотношением:
Найдём математические ожидания обеих частей этого равенства. По определению,
Математическое же ожидание правой части равенства по свойству математических ожиданий равно
Среднее квадратическое отклонение
Среднеквадратическое отклонение
равно квадратному корню из дисперсии:
При определении среднего квадратического отклонения при достаточно большом объеме изучаемой совокупности (n > 30) применяются формулы:
Похожая информация.